FlatBuffers
什么是FlatBuffers?
FlatBuffers是一个开源的、跨平台的、高效的、提供了C++/Java接口的序列化工具库。它是Google专门为游戏开发或其他性能敏感的应用程序需求而创建。尤其更适用于移动平台,这些平台上内存大小及带宽相比桌面系统都是受限的,而应用程序比如游戏又有更高的性能要求。它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而不需要任何解析开销。
FlatBuffers原理
person bean类:
class Person
{
String name;
int friendshipStatus;
Person spouse;
List<Person>friends;
}
原理图:
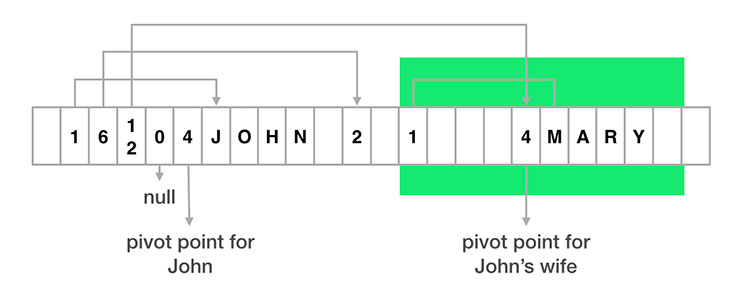
- 他将数据保存在一个一维的byte数组中;
- 每个实例对象以“支点”指针(pivot point)以此为界,存储的内容分为两个部分:
- 元数据:是bean中每个字段的指向数据内容的索引
- 数据内容:实际的对象的存储值
- Person 对象第一个字段是 name,其值的索引位置是 1,所以从索引位置 1 开始的字符串,就是 name 字段的值 "John"
- 如果对象字段没有内容,那么它的索引就是0
- 如果对象字段是另外个对象,它将指向另外一个支点的对象,如索引12
可以看出,FlatBuffers 通过自己分配和管理对象的存储,使对象在内存中就是线性结构化的,直接可以把内存内容保存或者发送出去,加载“解析”数据只需要把 byte 数组加载到内存中即可,不需要任何解析,也不产生任何中间变量。
FlatBuffers的优势
- 直接读取序列化数据,而不需要解析(Parsing)或者解包(Unpacking):FlatBuffer 把数据层级结构保存在一个扁平化的二进制缓存(一维数组)中,同时能够保持直接获取里面的结构化数据,而不需要解析,并且还能保证数据结构变化的前后向兼容。
- 高效的内存使用和速度:FlatBuffer 使用过程中,不需要额外的内存,几乎接近原始数据在内存中的大小。
- 强类型设计
FlatBuffers的使用方法
- 按照使用特定的 IDL 定义数据结构
schema;- 比如上面的javabean对应的schema可以,命名为
Person.fbs:// Person schema namespace com.race604.fbs; enum FriendshipStatus: int {Friend = 1, NotFriend} table Person { name: string; friendshipStatus: FriendshipStatus = Friend; spouse: Person; friends: [Person]; } root_type Person;
- 比如上面的javabean对应的schema可以,命名为
使用
flatc可以把 Schema 编译成多种编程语言,我们是 Android 平台,所以把 Schema 编译成 Java./flatc --java Person.fbs
会生成这样的文件的结构:

可以自己通过生成的java代码将数据添加到对象中,也可以从原来的json文件生成FlatBuffers数据文件
./flatc -j -b repos_schema.fbs repos_json.json
这样就会生成专门给FlatBuffers用的数据。
如何使用?
public void loadFromFlatBuffer(View view) { byte[] buffer = Utils.readRawResource(getApplication(), R.raw.sample_flatbuffer); long startTime = System.currentTimeMillis(); ByteBuffer bb = ByteBuffer.wrap(buffer); PeopleList peopleList = PeopleList.getRootAsPeopleList(bb); long timeTaken = System.currentTimeMillis() - startTime; String logText = "FlatBuffer : " + timeTaken + "ms"; textViewFlat.setText(logText); Log.d(TAG, "loadFromFlatBuffer " + logText); }通过代码构建数据:
private ByteBuffer createPerson() { FlatBufferBuilder builder = new FlatBufferBuilder(0); int spouseName = builder.createString("Mary"); int spouse = Person.createPerson(builder, spouseName, FriendshipStatus.Friend, 0, 0); int friendDave = Person.createPerson(builder, builder.createString("Dave"), FriendshipStatus.Friend, 0, 0); int friendTom = Person.createPerson(builder, builder.createString("Tom"), FriendshipStatus.Friend, 0, 0); int name = builder.createString("John"); int[] friendsArr = new int[]{ friendDave, friendTom }; int friends = Person.createFriendsVector(builder, friendsArr); Person.startPerson(builder); Person.addName(builder, name); Person.addSpouse(builder, spouse); Person.addFriends(builder, friends); Person.addFriendshipStatus(builder, FriendshipStatus.NotFriend); int john = Person.endPerson(builder); builder.finish(john); return builder.dataBuffer(); }FlatBuffers使用场景和缺陷
场景
- 项目中有大量数据传输和解析,使用 JSON 成为了性能瓶颈;
- 稳定的数据结构定义。
缺陷
- FlatBuffers 需要生成代码,对代码有侵入性
- 数据序列化没有可读性,不方便 Debug;
- 数据的所有内容需要使用 Schema 严格定义,灵活性不如 JSON