hash模块
Hash模块就是为我们更好的生成hash值。
Bloom Filters
为啥需要布隆过滤器?
布隆过滤器的出现是为了超长数据的查找问题。虽然链表、树、哈希表都是可以进行查找的,但是要么在空间上消耗很大,要么在时间上耗费很大。
而布隆过滤器的查找效率是O(1),空间消耗上也相对其他的要小一些。
基本原理?
准备一个长度为N的bit向量数组(尽量长),初始数组初始化为0###
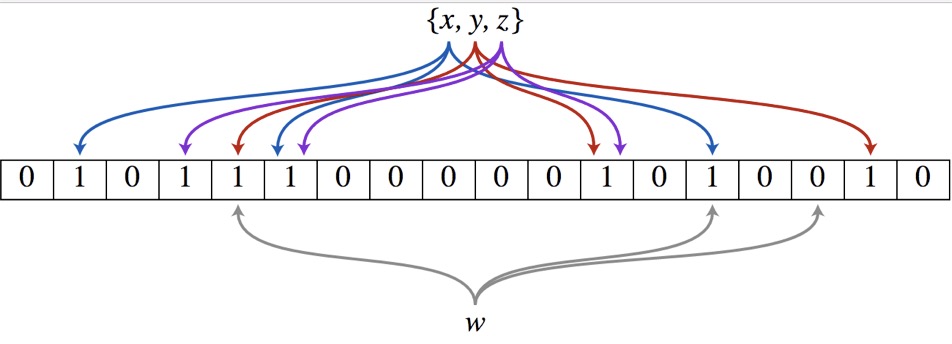
插入元素
- 将元素X分别给到K个哈希函数k1 k2 k3...进行哈希计算
- 得到的hash值就是就是bit数组上的一个点
- 将对应的bit数组上的点置为1
查询元素
- 将待查询的元素X分辨给K个哈希函数计算哈希值
- 如果k个位置上有1个为0,则次元素必不存在
- 如果k个位置上全部是1,则次元素可能存在
缺陷
- 数据一旦记录,无法删除
- 在查询存在的时候,存在一定的误判率
- bit数组的大小和哈希函数的个数难以确定
- bit数组的大小还是挺占空间的
bit数组大小的计算
应该是元素个数的1.44倍。具体的计算,读者可以查阅相关资料。
布隆过滤器的使用场景
- 字处理软件,检查拼写是否正确
- 犯罪嫌疑人是否在坏人名单上
- 一个网站是否被网络爬虫访问过
- 垃圾邮件、短信的过滤
BloomFilter.java
创建布隆过滤器
static <T> BloomFilter<T> create(
Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {
checkNotNull(funnel);
checkArgument(
expectedInsertions >= 0, "Expected insertions (%s) must be >= 0", expectedInsertions);
checkArgument(fpp > 0.0, "False positive probability (%s) must be > 0.0", fpp);
checkArgument(fpp < 1.0, "False positive probability (%s) must be < 1.0", fpp);
checkNotNull(strategy);
if (expectedInsertions == 0) {
expectedInsertions = 1;
}
/*
* TODO(user): Put a warning in the javadoc about tiny fpp values, since the resulting size
* is proportional to -log(p), but there is not much of a point after all, e.g.
* optimalM(1000, 0.0000000000000001) = 76680 which is less than 10kb. Who cares!
*/
long numBits = optimalNumOfBits(expectedInsertions, fpp);
int numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, numBits);
try {
return new BloomFilter<T>(new LockFreeBitArray(numBits), numHashFunctions, funnel, strategy);
} catch (IllegalArgumentException e) {
throw new IllegalArgumentException("Could not create BloomFilter of " + numBits + " bits", e);
}
}
其中需要关注的是bit数组和hash函数个数的计算:
static long optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
static int optimalNumOfHashFunctions(long n, long m) {
// (m / n) * log(2), but avoid truncation due to division!
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
使用的实例
BloomFilter filter = BloomFilter.create(Funnels.integerFunnel(), 500, 0.01);
filter.put(11);
filter.put(22);
Log.e("111", filter.mightContain(11) + " ===== ");
Log.e("111", filter.mightContain(121) + " ===== ");
扩扎阅读 —— BitSet
BitSet是按需增长的位向量,每个位用boolean值来表示,初始值都是false。
基本原理
BitSet是位操作的,值是false或true,内部维护了一个long的数组,缺省的数组的大小是64位,但是随着元素的增多,BitSet会自动的进行扩充。
用1位来表示一个数据是否出现过,0为没有出现过,1表示出现过。使用用的时候既可根据某一个是否为0表示,此数是否出现过。
举个例子,1G的空间,有8*1024*1024*1024=8.58*10^9bit,也就是可以表示85亿个不同的数。
使用的实例
public static void containChars(String str) {
BitSet used = new BitSet();
for (int i = 0; i < str.length(); i++)
used.set(str.charAt(i)); // set bit for char
StringBuilder sb = new StringBuilder();
sb.append("[");
int size = used.size();
System.out.println(size);
for (int i = 0; i < size; i++) {
if (used.get(i)) {
sb.append((char) i);
}
}
sb.append("]");
System.out.println(sb.toString());
}
Hash模块的架构

HashFunction
提供了无状态的方法,将任意的数据块映射固定数目的hash值。它的特点是保证相同的输入得到的hash输出一定是一样的,而不同的输入尽可能的保证不一样。
Hasher
有状态的方法,提供了方法将数据添加到散列运算中,Hasher可以接受所有原生类型、字节数组、字节数组的片段、字符序列、特定字符集的字符序列等等,或者任何给定了Funnel实现的对象。
Funnel
这个是将一个java对象拆分成原生字段值。它的定义是:
public interface Funnel<T> extends Serializable {
/**
* Sends a stream of data from the {@code from} object into the sink {@code into}. There is no
* requirement that this data be complete enough to fully reconstitute the object later.
*
* @since 12.0 (in Guava 11.0, {@code PrimitiveSink} was named {@code Sink})
*/
void funnel(T from, PrimitiveSink into);
}
Funnels是内置的,对装箱的对象,如Long、Integer进行的装换。
HashCode
hash计算后的输出结果。
Hash的使用
Funnel<Person> personFunnel = new Funnel<Person>() {
@Override
public void funnel(Person person, PrimitiveSink into) {
into.putInt(person.id)
.putString(person.firstName, Charsets.UTF_8)
.putString(person.lastName, Charsets.UTF_8)
.putInt(person.birthYear);
}
};
HashFunction hf = Hashing.md5();
Person person = new Person(1, "first", "last", 2018);
HashCode hc = hf.newHasher()
.putLong(1000)
.putString("test", Charsets.UTF_8)
.putObject(person, personFunnel)
.hash();
一般在使用Hash模块,都是从Hashing类开始调用,guava为我们提供了基本的一些散列的函数实现:
- MD5
- SHA_XXX
- CRC32
- ALDER32
- HMACXXX
- sipHash
另外,guava还实现了一致性hash的功能,具体不分析了。